What is Machine Learning, actually?
A simple, intuitive guide to artificial intelligence


The terms machine learning or artificial intelligence are thrown around a lot these days. It has become fashionable to say that such and such a device has artificial intelligence. But what does this mean?
My objective is to give a non-mathematical description of how AI algorithms work. Many papers on the topic quickly get bogged down in heavy duty mathematics, which I think obscures from the beauty of the algorithms.
We start with a ‘normal’ algorithm. An algorithm is a set of instructions that, given an input, will give a determined output. A simple example is an adding algorithm: you input two numbers and the algorithm spits out the sum of those numbers. Another way an algorithm can be viewed is as a classifier. We can consider the space of all possible inputs and the space of all possible outputs, also called labels. Then we can see an algorithm as a function assigning each point in input space the appropriate point in output space. We call the classifier h which maps from the input space to the output space. So in the case of our adding algorithm, the input space is all pairs of numbers and the output space is all the numbers.

Spice things up a bit
In the case of a normal algorithm, everything is determined. The classifier behaves in exactly the way we expect it to work. 2+3 will always come out as 5 (I have a degree in maths so I can say this with certainty). This algorithm is quite boring and easy to program. A programmer can write an explicit set of instructions on how to add two numbers together. But what if we consider something slightly more challenging? The classic example of number classification: I give you a hand written digit (0–9) and you have to tell me which one it is.

I defy anyone to write an explicit set of instructions that can classify a hand written digit with more accuracy than just assigning labels at random (which would be right 10% of the time).
Interestingly enough, humans can do this without any issues — are we smarter than computers? This is a question best asked to a philosopher and is a major digression from the topic at hand but is worth thinking about.
Let’s get learning
This is where machine learning comes in to play. We want an algorithm (or classifier) that gets fed training data and uses that to learn how to classify unseen images. An important feature of our classifier is that it must generalise the data. We don’t need it to fit the data perfectly but we want it to be able to handle unseen data with ease and accuracy.
The algorithm takes the image as input and will spit out a list of ten numbers between 0 and 1. Each number corresponds to a digit, the higher the number, the more confident the algorithm thinks it is that digit.
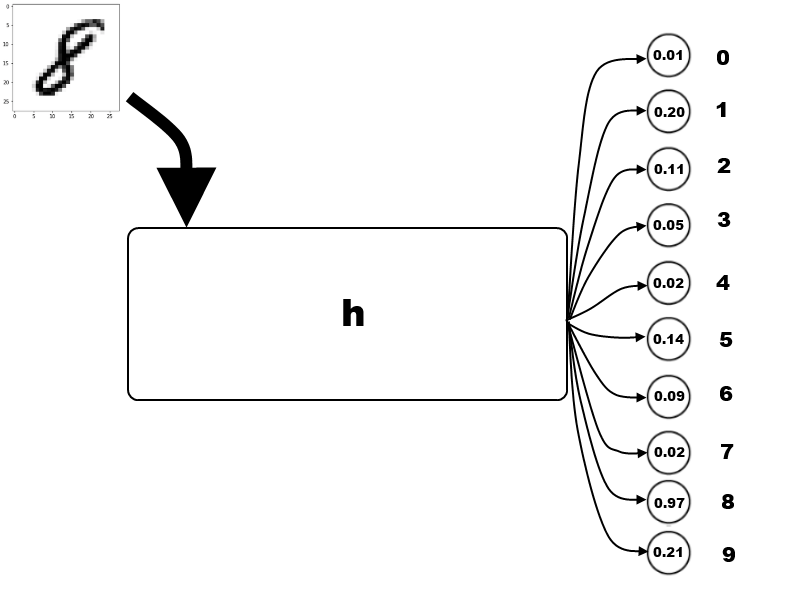
The classifier works by taking in the image but also has a bunch of parameters that we can play with to try and classify unseen images correctly.
Training wheels
Training data is images along with what digit it is — that is you already know the correct label. For example it would be an image of the number four along with the list (0,0,0,0,1,0,0,0,0,0) (recall that our algorithm spits out 10 numbers between 0 and 1 for the certainty that it is that digit). The algorithm then takes in the image and spits out its result. We need to then tell the classifier how ‘wrong’ it was, we call this the loss. One conventional way of doing this is by adding up the square of the differences, called quadratic loss. Say that the classifier spits out (0.43, 0.13, 0.05, 0.17, 0.57, 0.79, 0.70, 0.38, 0.93, 0.35). Then the loss would be 0.43² + 0.13² + 0.05² + 0.17² + (0.57–1)² + 0.79² + 0.70² + 0.38² + 0.93² + 0.35² giving a loss of 3.86 (2 d.p.). The aim is to obviously minimize the loss function, as it rewards the algorithm for accurately predicting what the number is but also rewards it for correctly identifying what it isn’t.
Minimize loss
So ideally we want to tweak the parameters of the classifier so that the loss function is zero on every training data. This is problematic for two reasons:
- We could be overfitting our data
- It is actually bloody difficult to do this
So we at least want to get the loss function to be pretty small on average. To do this we will apply gradient descent to the average loss function in parameter space (those of you that have read my article on dynamical systems will be familiar with gradient descent).
Instead of simply computing the loss for a specific input and set of parameters, we will compute the average loss for a specific set of parameters by averaging over all the training data. Remember the loss of a specific training data is just a number so taking the average is trivial (provided our data set is finite, mind you). In practice, it is inconvenient to take the average over all training data so we randomly choose a few pieces each time. So now we will consider the average loss where the input now is the parameters.
We look at the average loss function for every possible combination of parameters. In practice, we will only look at the loss function for parameters near those that are currently being used by our classifier.
Everything going downhill
The idea is that we look at how to make small nudges to our parameters that would have the biggest effect of decreasing the loss function. Or the direction of steepest descent of loss. We nudge the parameters a bit in that direction, then recompute the steepest descent and repeat the process. The analogy to keep in mind is that of a ball rolling down a mountain. At each point, it will go in the direction of steepest descent to try and minimize its altitude. We can think of the altitude of the ball as the loss — the higher it is the higher the loss, and the latitude and longitude as parameters. In this case there are only two parameters but in practice there can be hundreds of thousands.
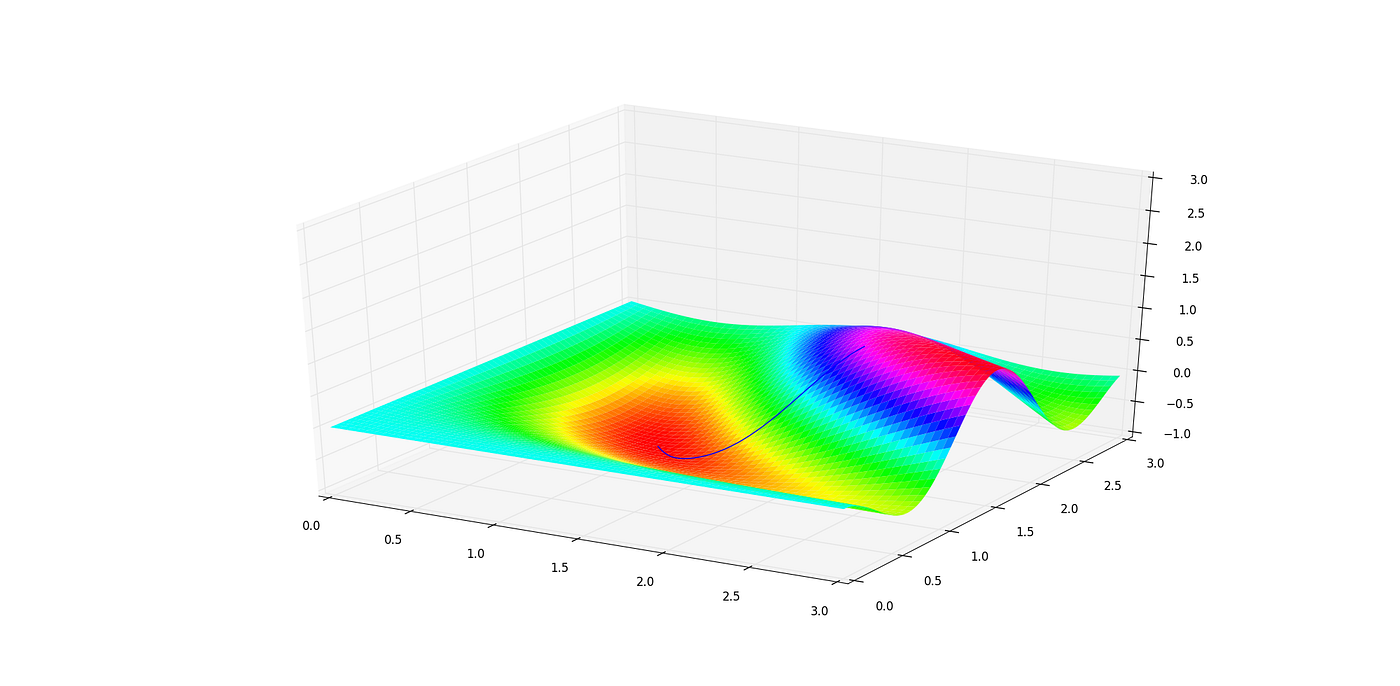
After applying gradient descent to our parameters, we reach a local minima of the loss function. That means we are doing the best we can for all parameters nearby. If the loss function at this minima turns out to be quite high (that is, it is not classifying inputs accurately) then tough luck. You could choose to start again with wildly different parameters and hope you don’t fall into the same local minima and also hope that the local minima you fall into is ‘better’ than the previous one. Turns out finding global minima is quite difficult.
Result!
Now we hopefully have a well-oiled algorithm that can classify hand written digits fairly confidently, by fairly confidently we mean that the average loss is low.
To recap:
- We start off with an algorithm that wildly guesses what each image is
- We feed it an image that we know what the answer is
- Then we compute how wrong it is
- According to how wrong it is and other mathematical mumbo-jumbo we slightly adjust the parameters in the algorithm to decrease the wrongness
- Rinse and repeat steps 2–4
And that is it! That is fundamentally how machine learning works. This is the blandest sort of machine learning algorithm called neural network. We can always spice things up after but this is the core principles of how most artificial intelligences learn.
The whole structure of how a neural network learns is somewhat similar to how a baby learns. A baby is inquisitive about the world around it, maybe it puts its hand on top of the stove and burns itself. This is considered a high loss. But the baby then adjusts its brain to tell it not to do that again. Similarly, if the baby does its business in the toilet, it will get a reward — a low loss. It will then learn to repeat that. And so a human is formed that behaves as expected and can generalise to unfamiliar situations: you don’t have to teach an adult to use the toilet in a house they have never been to before.
So in many ways AI mimics the way humans learn to try and teach a bunch of computer transistors how to ‘think’. But is this any different to a bunch of neurons thinking?