Neural Quine: Is Self-Replicating AI Real?
A story on reproduction in biology, machines, and AI

A story on reproduction in biology, machines, and AI
We are already used to see the impact of AI everywhere around us not just in digital life (from recommendations on Netflix to voice recognition by Siri and Alex) but also in physical: Amazon Go, CCTV surveillance and taxis without drivers and it indeed made our lives better. What is a bit disappointing, that the “intelligence” doesn’t seem anything like a human or even biological intelligence, because it is just a set of mathematical models that have been fit their degrees of freedom based on some empirical observations. What do we expect from the intelligent creature? Apart from the raw intelligence, it could probably sense of humor, compassion, ability to interpret its own decisions and, of course, the ability to reproduce. Everything but the latter point was already successfully implemented in some algorithmic form, that’s why this article will focus on trying to build such AI (an artificial neural network here) that is able to copy itself, i.e. is able to self-replication as the simplest form of reproduction.
We will review the history of self-replicating machines, the corresponding concepts and will code our own neural networks that are able to do it. During this research, very interesting but natural questions will arise: is this self-replication even useful for the algorithms? How they balance between reproduction and other tasks we want to teach them? Probably, we can learn something from this experiment as humans? This article is highly influenced by the work Neural Quines. As always, you can find all the source code and try the experiment by yourself in my GitHub.
Self-replication in nature
As Wikipedia tells us, in nature the process of replication is essentially the reproduction:
Reproduction (or procreation or breeding) is the biological process by which new individual organisms — “offspring” — are produced from their “parents”. Reproduction is a fundamental feature of all known life; each individual organism exists as the result of reproduction. There are two forms of reproduction: asexual and sexual.
The creation of the “offsprings” that are different from the parents is the topic of another discussion, but self-replication was actually the very first biological act of reproduction. It was the very dawn of evolution and natural selection made the job pushing such creatures that were better replicating themselves. Thanks to the randomness and mutation the first simple cells appeared. Everything else is history.
Self-replicating machines
Rather scary mechanical self-reproduction from Cornell University
One of the first, celebrated John von Neumann started to think of a machine, that is also is able to create its offsprings or at least to copy itself. As a base model, he selected (pretty obvious for his time) a Turing Machine and tried to build such automata (he called it Universal Constructor A). The very first iteration looked like the following:

Von Neumann meant to create a Turing Machine A that creates another automata X based on the instruction Ф(X) but realized that it is not enough for reproduction because apart of creating the automata X you also need to create the instruction Ф(X) for the future “babies”.
Next step he called Universal Copier B:

This is basically a “Turing Quine” that literally outputs its own source code, in our case, the instruction Ф(X). What’s next? Exactly, somehow we need to combine Universal Constructor A and Universal Copier B. Unfortunately we can’t just combine them in the (A+B) mode, because then what happens if the description Φ(A + B) is input into the automaton (A + B)? The result should be an extra copy of both the automaton and its description.
Again, Von Neumann envisioned a third control automaton C with executive control over the activities of (A + B) to ensure that the symbolic input description Φ(A + B) is used in the correct role at the correct time, i.e., either to construct or to copy. Check the paper to see the explanation of why three sub-assembly automata (A + B + C) is actually enough for the simplest self-replicating Turing machine, which is easy though.
Why do we need self-reproducing AI?
Seems like the idea of self-replication makes sense in nature (thanks cap) and in algorithms on different scales. But why do we need it in the AI programs?
- If biological life began with the first self-replicator, so if we are already inspired by biological methods in creating artificial intelligence, shouldn’t we kick-off with the same starting point?
- The latest research in neural networks is very focused on the right representation learning, that’s why many hypotheses to influence the weights like generative or multitask modeling are on fire today. Shouldn’t self-awareness and self-replication be such a representation goal as well?
- It is important also for security, for instance, if an AI program can output it’s own “source code” and, hence, block other opportunities to read the weights from the file or reverse-engineer it somehow.
- Another nice property of a self-reproducing system is the ability to self-repair from the damages as some living creatures already do.
- Apart from technological challenges, humans tend to like becoming all-mighty gods and creating something that is able to recreate itself can look attractive from the “artificial life creating” point of view.
Quines
Talking about computer programs, such ones that are able to replicate themselves (i.e. to return their own source code) are known for some time as quines. For example, in Python, the code that outputs itself may look like the following, you can find more theory and sophisticated examples here:
s = ’s = %r\nprint(s%%s)’
print(s%s)
Talking about neural networks and machine learning models, we can consider as a neural quine such a model, that is able to reproduce its all its own parameters and structure very accurately. It means, having a multilayer perceptron, it has to be able to return all the weight matrices and biases vectors of itself.
The name “quine” was coined by Douglas Hofstadter, in his popular science book Gödel, Escher, Bach, in honor of philosopher Willard Van Orman Quine (1908–2000), who made an extensive study of indirect self-reference, and in particular for the following paradox-producing expression, known as Quine’s paradox: “Yields falsehood when preceded by its quotation” yields falsehood when preceded by its quotation.
In our case of machine learning quines, we have several challenges upcoming:
- How to define a mathematical setup that will allow a neural network to predict its own weights?
- How to make such a neural network to solve other, useful tasks, meanwhile being able to reproduce itself?
- Having built such a model, what does this self-replication mean? Does it help the training? What do we learn from it?
Neural Quines
Alright, so we agreed on having a neural network that predicts its weights as a neural quine. What is our next step? Correct, to predict directly the weights for example as a set of matrices with a mean squared error as a loss function… but here are several problems. First of all, the size of the output will be a lot of times larger than input size: this itself will lead to difficulties in convergence. Another point is when dealing with multilayer networks: should we set it up as multitask learning with having each separate weight matrix as a separate task? Or what should we do with convolutional or recurrent architectures? Seems like we need some indirect way to predict the weights.
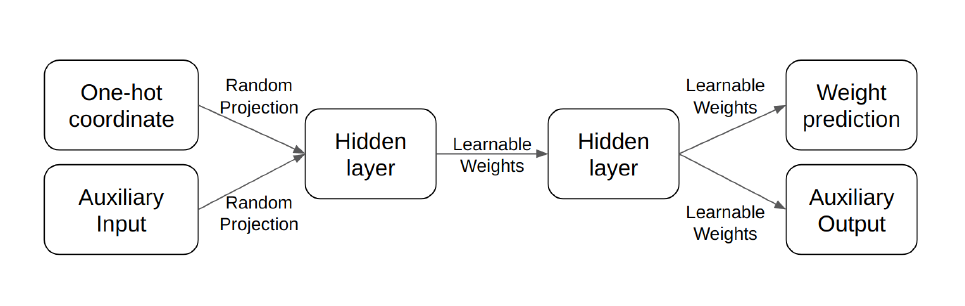
The idea described in the original Neural Quines paper is indeed brilliant and is inspired by the HyperNEAT, a neuroevolution method for designing neural architectures. Instead of predicting all weights in the output same time, we can use the coordinate (or index) of each weight as the input and have a single number that represents the value of this weight as the output. This way we ensure the smallest possible dimension both for the input and the output without any constraint on the inner architecture and, hence, the weights! Schematically, the architecture will look like the following:

But what should we do in the case when apart of self-replication we would like to solve some additional classification or regression problem? Thanks to the flexibility of the graph-based neural architectures and the ideas of multimodal and multitask learning, we can do that as well:
Mathematically, we have a loss suitable for regression to measure the deviation between the actual weights of the model and predicted ones
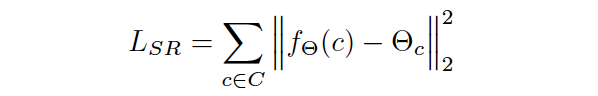
and in case of solving additional task next to the self-replication (authors call it auxiliary), we can add it in the multitask manner with some regularization coefficient:
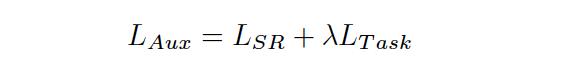
In PyTorch code, the architecture will look like the following (also, check the source code on GitHub):
AuxiliaryQuine(
(embedding): Embedding(4096, 64)
(linear): Linear(in_features=64, out_features=64, bias=False)
(output): Linear(in_features=64, out_features=1, bias=False)
(class_output): Linear(in_features=64, out_features=10, bias=False)
)
To learn more about multitask learning and its benefits, please check out this article of mine, it shows some examples in time series analysis and computer vision alongside the source code!
Experiments
For testing out the idea I chose relatively simple multilayer perceptrons with a single hidden layer. As an auxiliary classification task, I’ve played with an MNIST dataset with pictures rescaled to 8x8 pixels to speed up the convergence and keep a number of weights to be replicated very limited (<5000). There can be several setups on how to train neural quines. Again, the authors of the paper show that there are possibilities to train these neural networks as we “used to”: using gradient-based approaches and backpropagation and evolutionary algorithms. Both of these approaches are focused on optimizing for self-replicating loss directly. But apart from that, there exists also the so-called regeneration method:
We do so by replacing the current set of parameters with the weight predictions made by the quine. Each such replacement is called regeneration. We then alternate between executing regeneration and a round of optimization to achieve a low but non-trivial self-replicating loss.
We test out all the approaches to understand to which solutions they converge because as you might already guess, and know from practice, that machine learning models tend to converge to the easiest possible solutions. In our case, such a solution could appear if all our weights are equal to zero :) You can try all the results with the PyTorch code here.
Vanilla neural quine
Let’s start with a “regular” neural quine that just learns to predict its own weights. We can do it with the single hidden layer perceptron that has 10000 parameters:
VanillaQuine(
(embedding): Embedding(10000, 100)
(linear): Linear(in_features=100, out_features=100, bias=False)
(output): Linear(in_features=100, out_features=1, bias=False)
)
and train it first with regular gradient-based optimization. What did we train after all?
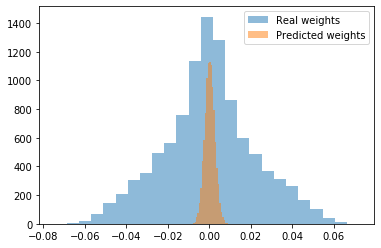


As we can see, visually, we haven’t predicted the weights very well. The mean average error and mean square error are far from zero as well (0.012, 0.0005 respectively). Let’s try the regeneration method then?
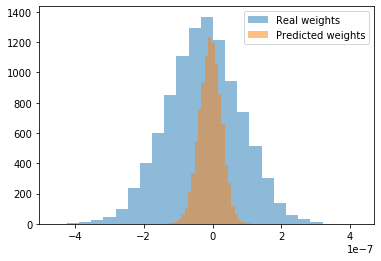


It seems like from the metrics (MAE 6.490128e-08, MSE 6.623671e-15) and visual picture we actually can predict the weights very well… but wait, if they all are almost equal to zero, it seems like our regeneration neural quine simply converged to so-called trivial zero quine! The effect of shrinking the weights to have a magnitude of very close to zero is already known in regularization theory which is definitely a good thing, but we still need to check out if it actually helps the training some standard machine learning task as it happens with regularization. Otherwise, I will start questioning myself if we need reproduction at all if it doesn’t help to achieve the goals (at least in terms of AI)…
Auxiliary quine
Let’s try now to add some additional task to our quine and see how the self-replicating goal can co-survive with some classification, let’s say, of the MNIST numbers :) For simplicity of visualization and convergence I’ve reduced the images to 8x8 pixels, which, hence, didn’t affect the accuracy of regular neural network that much. The architecture is the following:
AuxiliaryQuine(
(embedding): Embedding(4096, 64)
(linear): Linear(in_features=64, out_features=64, bias=False)
(output): Linear(in_features=64, out_features=1, bias=False)
(class_output): Linear(in_features=64, out_features=10, bias=False)
)
Also, I have compared different coefficients lambda next to the classification loss — to understand better if we need to balance the trade-off between self-reproduction and another task.
Seems like these models are able to predict the weights very-very accurate, but what about the accuracies? On the test dataset, they are respectively 0.8648, 0.847, and 0.8455… not that much, but at least let’s compare it with a vanilla MLP who doesn’t learn to predict it’s own weights!
Solo classification
The distribution of weights magnitudes, in this case, is much higher so it can give us the illusion that, we have regularized our model better within the self-replication framework, but the test accuracy is much higher — 0.9382! Seems like self-replicating didn’t help in learning other tasks in any way. What’s interesting though, that seems like adding an auxiliary task actually helped regeneration task to converge to the better self-replication as we can see from the histogram!
Conclusions
Apart from solving an interesting exercise in the machine learning world, we figured out several interesting findings related to self-replication in AI algorithms. First of all, we clearly see, that vanilla quine tends to converge very quickly to the trivial solution with zero weights, which even looks similar to regularization, has completely different meanings. Instead of getting rid of the weights that are redundant for the loss optimization, self-replication simply cuts them to zero because it’s easier to learn. This is not something that we want :)
Secondly, even having stated self-awareness as an ability to predict its own weights, this task takes too much capacity of the neural network. We can clearly see it from the reduced accuracies of the MNIST auxiliary neural network. Again, on the contrary to the regularization, self-replication didn’t help to train in any way.
Last but not least, it made me think about this trade-off between self-replication and goals achieving in real life. Are we, humans, following the same logic? Is our natural calls “distracting” us from the other goals and take too much capacity in our neural networks? This is a nice point to discuss ;)
I hope, that this small experiment can inspire you to different ideas on how to inject the idea of self-consciousness and, probably, even self-replication to the machine learning algorithms. Ping me if you figured out something interesting, I am open to various collaborations and experiments!